查询优化器
对于优化器,(主要是因为一直有很强的队友顶在前面)我自己并没有做过特别系统的学习,谈不上有太多一线经验,这里只整理一些我觉得有价值的资料和线索。
优化器基础
PostgreSQL 优化器的整体思路源自经典的 System R:基于统计信息做代价估算(CBO),在 join order 上,小规模场景主要依赖动态规划,而在 join 关系很多时则会回退到 GEQO。
对于 GP,则是在 PG 单机计划的基础上插入 motion(exchange)节点,把它改造成一个分布式并行计划。除了沿用 PG 的优化器之外,还可以选用著名的 ORCA 优化器:它基于更现代的 Volcano/Cascades 模型,采用自顶向下的规划方式。
优化器的整体架构和背景知识,可以参考 PolarDB 的两篇文章:<1>,<2>。
深入代码
代码细节可以参考树杰的《PostgreSQL 技术内幕之查询优化》。
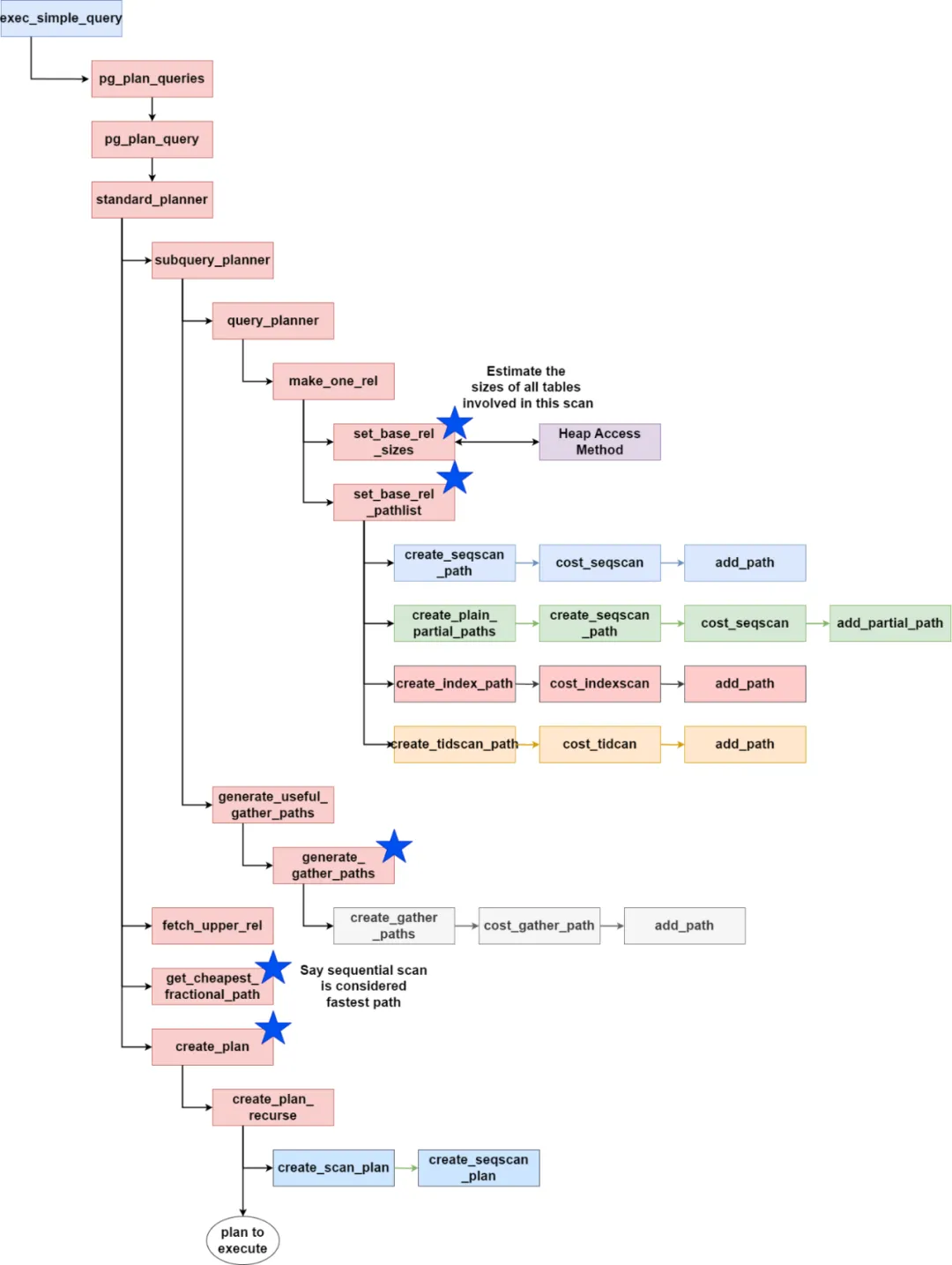
★优化器代码执行的大致脉络如下:
standard_planner() // 主入口
subquery_planner() // 逻辑重写
├─ 处理 CTE/MERGE/空FROM
├─ 提升 SubLinks/Subqueries
├─ 统计 rtable 信息
├─ 预处理 RowMark
├─ 表达式预处理
├─ HAVING转移到WHERE
├─ OUTER JOIN简化
├─ 删除无用 RTE_RESULT
└─ grouping_planner() // plan主逻辑
query_planner()
├─ 处理 targetlist、jointree、placeholder
├─ 生成 joinlist
├─ 外连接和等价类处理
├─ 计算 pathkeys
├─ 处理 placeholder 依赖
├─ 移除无用 join
├─ 分发 placeholder
├─ 构建 lateral 信息
├─ 外键与 join 约束匹配
├─ OR 条件处理
├─ 扩展 appendrels
└─ make_one_rel(root, joinlist) // join规划和路径生成 => RelOptInfo
get_cheapest_fractional_path() // 获取最优路径
(gp独有步骤:调用cdbparallelize()将plan并行化)
create_plan() // 将path转换成plantree,封装成PlannedStmt返回给执行器
★函数栈调用示例(图片来源)
★主要结构体
比如 Query、Path、RelOptInfo 等,这里后续再单独补。
Discussion
在我目前的理解里,优化器最核心要解决两类问题:
- 选择率估计:依赖统计信息。此前 GP 上很多客户 case,本质上都是统计信息不准导致的误判。
- join order:PG 目前主要是动态规划 + GEQO,而更现代的做法可以参考 DPccp 论文。
由于相关概念都比较抽象,想真正掌握优化器,必须结合具体 case 来看。这里有几篇 Doris 的优化经验文章,质量很高:<1>,<2>。
Questions:
- 多表 join 的结果估计:例如两个表做 join,优化器如何估算结果行数?
提示:必然要通过统计信息,具体需要那种?
- 代码练习:新增一个 plan 节点。
可以考虑新增一个 SQL 语法 + 一个 plan 节点 + 一个执行器节点,完整走一遍 query 处理流程。